Prompts overview and use cases
Use Prompts to evaluate and refine your LLM prompts and then generate predictions to automate your labeling process.
All you need to get started is an LLM deployment API key and a project.
With Prompts, you can:
- Drastically improve the speed and efficiency of annotations, transforming subject matter experts (SMEs) into highly productive data scientists while reducing the dependency on non-SME manual annotators.
- Increase annotation throughput, accuracy, and consistency, making the process faster and more scalable.
- Empower users to harness the full potential of AI-driven text labeling, setting a new standard for efficiency and innovation in data labeling.
- Leverage subject matter expertise to rapidly bootstrap projects with labels, allowing you to decrease time to ML development.
- Allow your subject matter experts time focus on higher-level tasks rather than being bogged down by repetitive manual work.
Use cases
Auto-labeling with Prompts
Prompts allows you to leverage LLMs to swiftly generate accurate predictions, enabling instant labeling of thousands of tasks.
By utilizing AI to handle the bulk of the annotation work, you can significantly enhance the efficiency and speed of your data labeling workflows. This is particularly valuable when dealing with large datasets that require consistent and accurate labeling. Automating this process reduces the reliance on manual annotators, which not only cuts down on labor costs but also minimizes human errors and biases. With AI’s ability to learn from the provided ground truth annotations, you can maintain a high level of accuracy and consistency across the dataset, ensuring high-quality labeled data for training machine learning models.
Workflow
If you don’t already have one, create a project and import a text-based dataset.
Annotate a subset of tasks, marking as many as possible as ground truth annotations. The more data you have for the prompt evaluation, the more confident you can be with the results.
If you want to skip this step, see the bootstrapping use case outlined below.
Go to the Prompts page and create a new Prompt. If you haven’t already, you will also need to add an API key to connect to your model.
Write a prompt and evaluate it against your ground truth dataset.
When your prompt is returning an overall accuracy that is acceptable, you can choose to apply it to the rest of the tasks in your project.
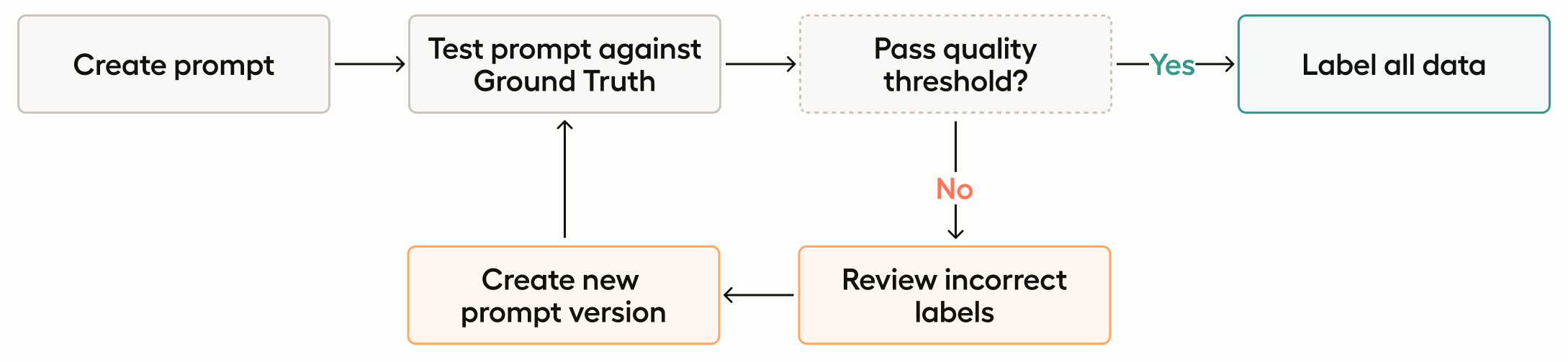
Bootstrapping projects with Prompts
In this use case, you do not need a ground truth annotation set. You can use Prompts to generate predictions for tasks without returning accuracy scores for the predictions it generates.
This use case is ideal for organizations looking to kickstart new initiatives without the initial burden of creating extensive ground truth annotations, allowing you to start analyzing and utilizing your data immediately. This is particularly beneficial for projects with tight timelines or limited resources.
By generating predictions and converting them into annotations, you can also quickly build a labeled dataset, which can then be refined and improved over time with the help of subject matter experts. This approach accelerates the project initiation phase, enabling faster experimentation and iteration.
Additionally, this workflow provides a scalable solution for continuously expanding datasets, ensuring that new data can be integrated and labeled efficiently as the project evolves.
note
You can still follow this use case even if you already have ground truth annotations. You will have the option to select a task sample set without taking ground truth data into consideration.
Workflow
If you don’t already have one, create a project and import a text-based dataset.
Go to the Prompts page and create a new Prompt. If you haven’t already, you will also need to add an API key to connect to your model.
Write a prompt and run it against your task samples.
When you run your prompt, you create predictions for the selected sample (this can be a portion of the project tasks or all tasks). From here you have several options:
- Continue to work on your prompt and generate new predictions each time you run it against your sample.
- Return to the project and begin reviewing your predictions. If you convert your predictions into annotations, you can use subject matter experts and annotators to begin interacting with those the annotations.
- As you review the annotations, you can identify ground truths. With a ground truth dataset, you can further refine your prompt using its accuracy score.

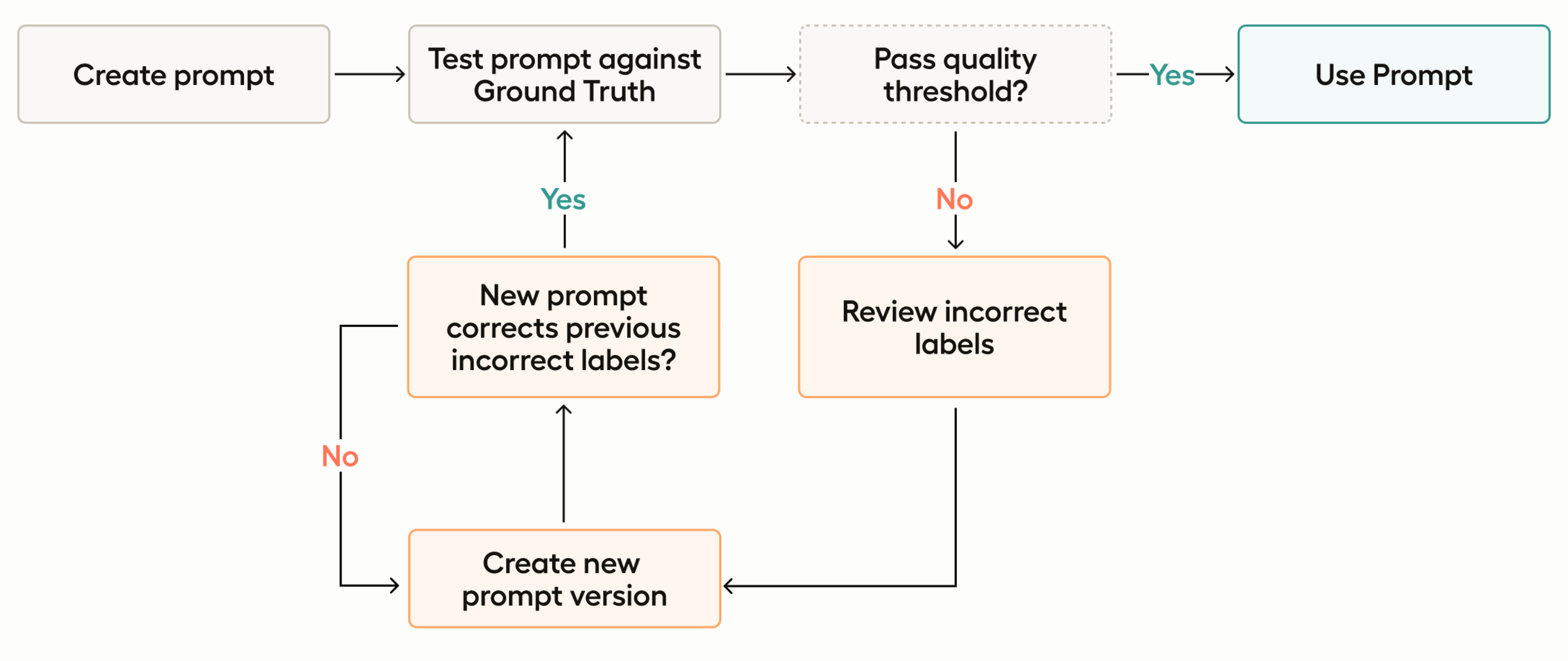
Prompt evaluation and fine-tuning
As you evaluate your prompt against the ground truth annotations, you will be given an accuracy score for each version of your prompt. You can use this to iterate your prompt versions for clarity, specificity, and context.
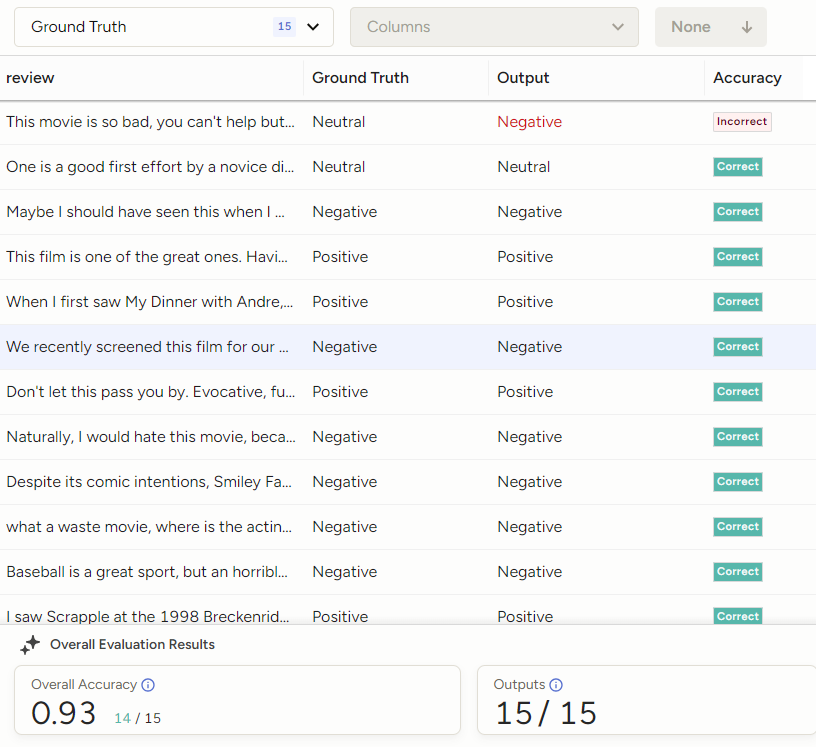
This accuracy score provides a measurable way to evaluate and refine the performance of your prompt. By tracking accuracy, you can ensure that the automated labels generated by the LLM are consistent with ground truth data.
This feedback loop allows you to iteratively fine-tune your prompts, optimizing the accuracy of predictions and enhancing the overall reliability of your data annotation processes. In industries where data accuracy directly impacts decision-making and operational efficiency, this capability is invaluable.
Workflow
If you don’t already have one, create a project and import a text-based dataset.
Annotate a subset of tasks, marking as many as possible as ground truth annotations. The more data you have for the prompt evaluation, the more confident you can be with the results.
Go to the Prompts page and create a new Prompt. If you haven’t already, you will also need to add an API key to connect to your model.
Write a prompt and evaluate it against your ground truth dataset.
Continue iterating and refining your prompt until you reach an acceptable accuracy score.
Features, requirements, and constraints
| Feature | Support |
|---|---|
| Supported data types | Text |
| Supported object tags | Text HyperText |
| Supported control tags | Choices Labels TextArea Pairwise Number Rating |
| Class selection | Multi-selection (the LLM can apply multiple labels per task) |
| Supported base models | OpenAI gpt-3.5-turbo-16k* OpenAI gpt-3.5-turbo* OpenAI gpt-4 OpenAI gpt-4-turbo OpenAI gpt-4o OpenAI gpt-4o-mini Azure OpenAI chat-based models Custom LLM Note: We recommend against using GPT 3.5 models, as these can sometimes be prone to rate limit errors. |
| Text compatibility | Task text must be utf-8 compatible |
| Task size | Total size of each task can be no more than 1MB (approximately 200-500 pages of text) |
| Network access | If you are using a firewall or restricting network access to your OpenAI models, you will need to allow the following IPs: 3.219.3.197 34.237.73.3 4.216.17.242 |
| Required permissions | Owners, Administrators, Managers – Can create Prompt models and update projects with auto-annotations. Managers can only apply models to projects in which they are already a member. Reviewers and Annotators – No access to the Prompts tool, but can see the predictions generated by the prompts from within the project (depending on your project settings). |
| ML backend support | Prompts should not be used with a project that is connected to an ML backend. |
| Enterprise vs. Open Source | Label Studio Enterprise (Cloud only) Starter Cloud |